index
Source URL: https://docs.bullmq.io/bullmq-pro/groups
그룹을 사용하면 단일 큐를 유지하면서 작업을 그룹별로 분배하여, 각 그룹에 속한 작업이 서로에 대해 하나씩 순차적으로 처리되도록 할 수 있습니다.
예를 들어, 모든 사용자의 비디오 트랜스코딩을 처리하는 큐가 1개 있고, 애플리케이션에는 수천 명의 사용자가 있다고 가정해 봅시다. 트랜스코딩은 시간이 오래 걸리고 CPU를 많이 사용하므로 이 작업을 오프로딩해야 합니다. 많은 사용자가 많은 파일의 트랜스코딩을 요청하면, 그룹이 없는 큐에서는 한 사용자가 큐를 작업으로 가득 채울 수 있고, 다른 사용자들은 그 사용자의 모든 작업이 끝날 때까지 자신의 작업이 처리되기를 기다려야 합니다.
그룹은 모든 사용자 간에 작업이 “라운드 로빈” 방식으로 처리되므로 이 문제를 해결합니다.
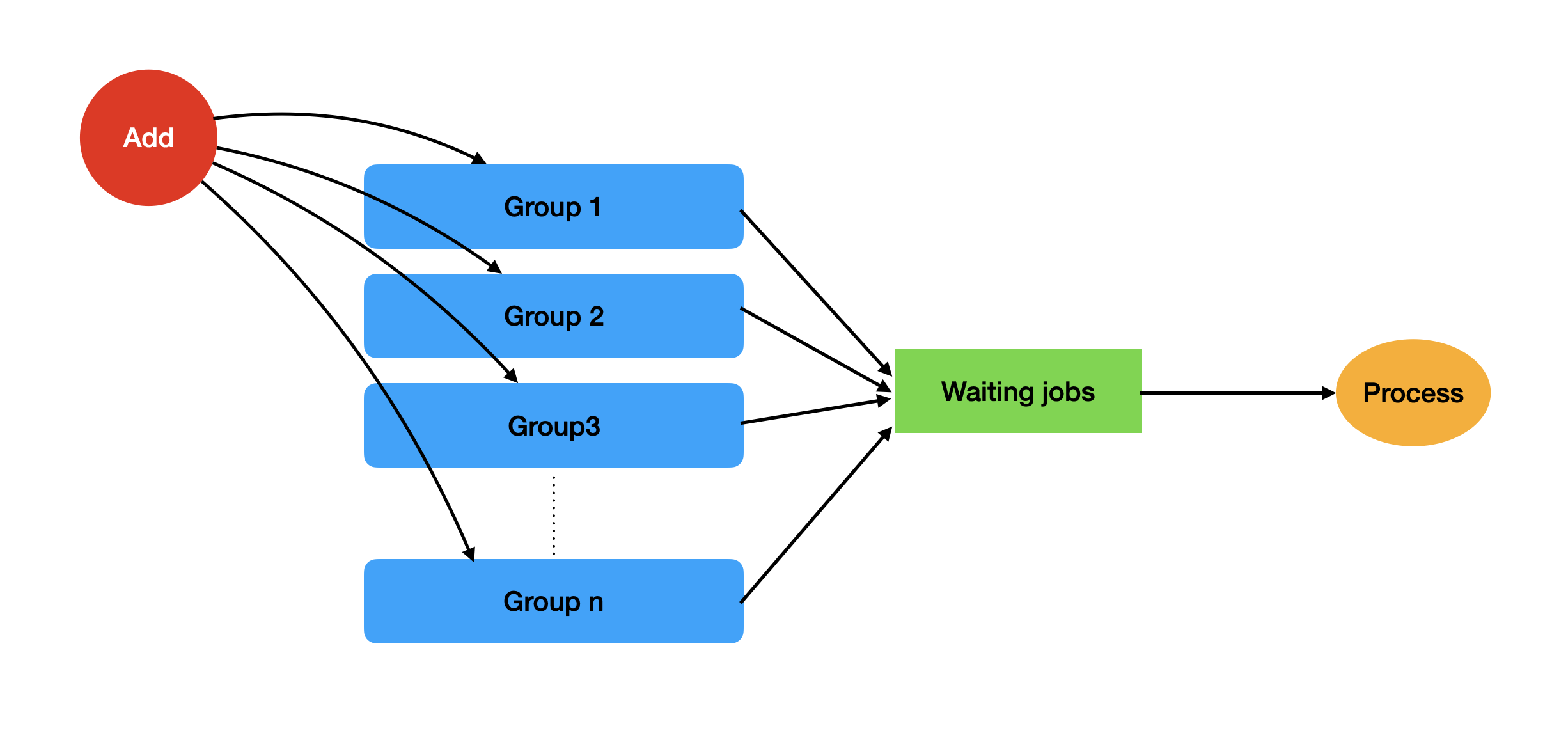
여러 워커를 사용하거나 동시성 계수가 1보다 크면 작업은 병렬로 처리됩니다. 다만 작업은 앞서 설명한 대로 그룹에서 라운드 로빈 순서를 따라 가져옵니다.
물론 원하는 만큼 워커를 둘 수 있으며, 큐에 대기 중인 작업 수에 따라 워커 수를 스케일 업/다운할 수도 있습니다.
큐에서 그룹 작업만 사용하는 경우 대기 작업 목록은 늘어나지 않고, 대신 처리할 다음 작업(있다면)만 유지됩니다. 하지만 같은 큐에 비그룹 작업을 추가할 수 있으며, 이 작업들은 각 그룹에서 대기 중인 작업보다 우선 처리됩니다.
{% hint style=“info” %} 생성할 수 있는 그룹 수에는 하드 제한이 없으며, 성능에도 영향을 주지 않습니다. 그룹이 비어 있으면 해당 그룹 자체는 Redis 리소스를 소비하지 않습니다. {% endhint %}
그룹을 보는 또 다른 방식은 “가상” 큐로 보는 것입니다. 즉, “사용자”마다 큐를 하나씩 두는 대신 사용자마다 “가상” 큐를 두어 모든 사용자의 작업이 더 예측 가능하게 처리되도록 합니다.
그룹 기능을 사용하려면 작업 추가 시 작업 옵션의 group 속성을 사용하세요:
import { QueuePro } from '@taskforcesh/bullmq-pro';
const queue = new QueuePro();
const job1 = await queue.add( 'test', { foo: 'bar1' }, { group: { id: 1, }, },);
const job2 = await queue.add( 'test', { foo: 'bar2' }, { group: { id: 2, }, },);작업을 처리하려면 표준 워커를 사용할 때와 마찬가지로 pro worker를 사용하세요:
import { WorkerPro } from '@taskforcesh/bullmq-pro';
const worker = new WorkerPro('test', async job => { // Do something usefull.
// You can also do something different depending on the group await doSomethingSpecialForMyGroup(job.opts.group);});