introspection이란 무엇인가요?
출처 URL: https://docs.prisma.io/docs/orm/prisma-schema/introspection
introspection이란 무엇인가요?
섹션 제목: “introspection이란 무엇인가요?”데이터베이스를 introspect하여 Prisma schema에 데이터 모델을 생성하는 방법을 알아보세요.
Prisma schema에서 data model을 생성하기 위해 Prisma CLI를 사용해 데이터베이스를 introspect할 수 있습니다. 데이터 모델은 Prisma Client 생성에 필요합니다.
Introspection은 기존 프로젝트에 Prisma ORM을 추가할 때 데이터 모델의 초기 버전을 생성하는 데 자주 사용됩니다.
하지만 애플리케이션에서 반복적으로 사용할 수도 있습니다. 이는 Prisma Migrate를 사용하지 않고 일반 SQL이나 다른 마이그레이션 도구로 스키마 마이그레이션을 수행할 때 가장 흔합니다. 이 경우 Prisma Client API에 스키마 변경 사항을 반영하려면 데이터베이스를 다시 introspect하고 이후 Prisma Client를 다시 생성해야 합니다.
introspection은 무엇을 하나요?
섹션 제목: “introspection은 무엇을 하나요?”Introspection의 핵심 기능은 하나입니다: 현재 데이터베이스 스키마를 반영하는 데이터 모델로 Prisma schema를 채우는 것입니다.
다음은 SQL 데이터베이스에서의 주요 기능 개요입니다:
- 데이터베이스의 tables 를 Prisma models로 매핑
- 데이터베이스의 columns 를 Prisma model의 fields로 매핑
- 데이터베이스의 indexes 를 Prisma schema의 indexes로 매핑
- database constraints 를 Prisma schema의 attributes 또는 type modifiers로 매핑
MongoDB에서의 주요 기능은 다음과 같습니다:
- 데이터베이스의 collections 를 Prisma models로 매핑. MongoDB의 collection 은 미리 정의된 구조가 없기 때문에, Prisma ORM은 컬렉션의 documents 를 샘플링 하여 그에 맞게 모델 구조를 도출합니다(즉, document 의 필드를 Prisma model의 fields로 매핑). 컬렉션에서 embedded types 가 감지되면 Prisma schema의 composite types로 매핑됩니다.
- 컬렉션에 인덱스에 포함된 필드를 가진 문서가 하나 이상 있을 경우, 데이터베이스의 indexes 를 Prisma schema의 indexes로 매핑
데이터베이스 타입이 Prisma schema에서 사용 가능한 타입으로 어떻게 매핑되는지에 대한 자세한 내용은 각 데이터 소스 커넥터 문서를 참고하세요:
- PostgreSQL
- MySQL
- SQLite
- Microsoft SQL Server
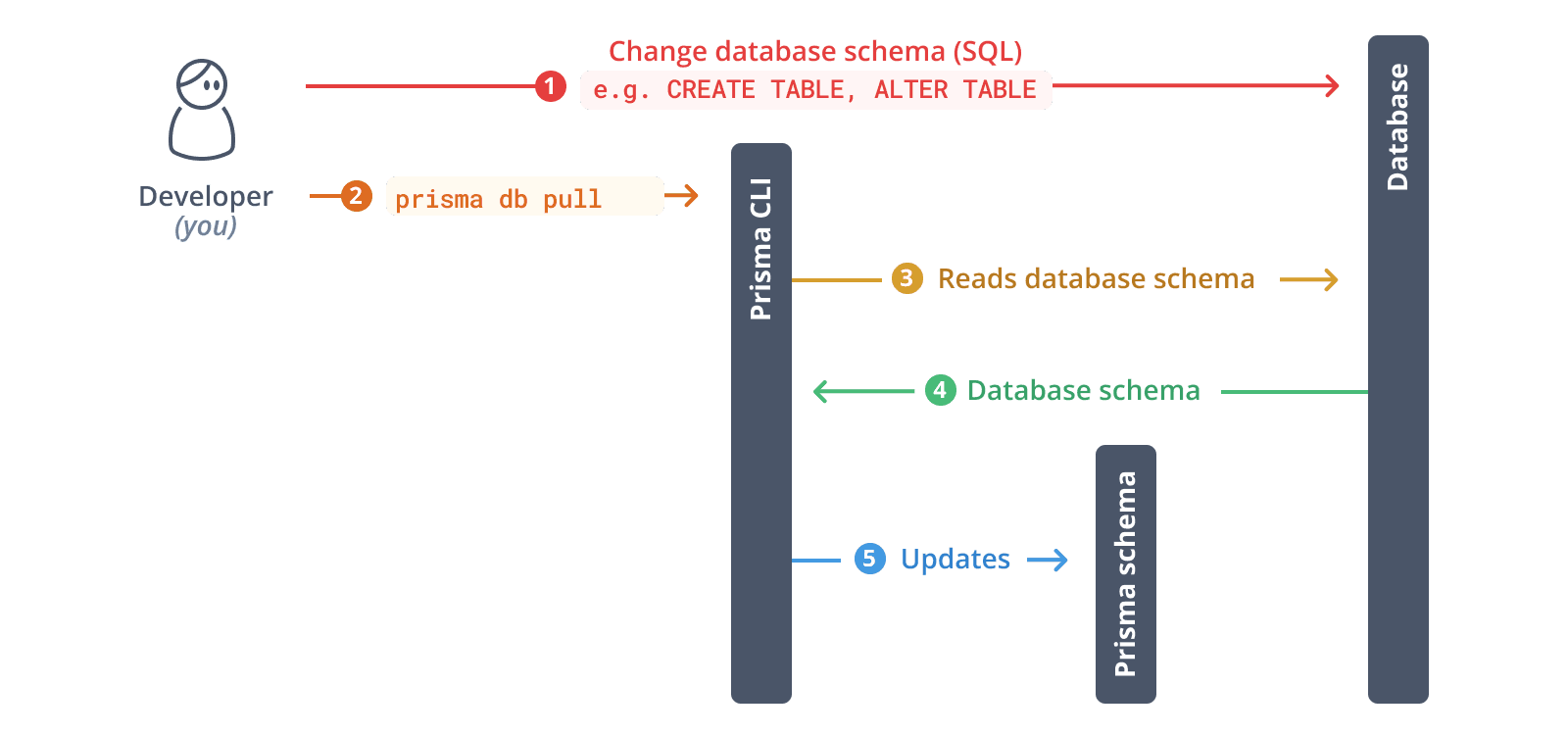
prisma db pull 명령어
섹션 제목: “prisma db pull 명령어”Prisma CLI의 prisma db pull 명령어를 사용해 데이터베이스를 introspect할 수 있습니다. 이 명령어를 사용하려면 Prisma config의 datasource에 connection URL이 설정되어 있어야 합니다.
다음은 prisma db pull 이 내부적으로 수행하는 단계의 상위 수준 개요입니다:
- Prisma config의
datasource설정에서 connection URL 읽기 - 데이터베이스 연결 열기
- 데이터베이스 스키마 introspect(즉, 테이블, 컬럼 및 기타 구조 읽기 …)
- 데이터베이스 스키마를 Prisma schema 데이터 모델로 변환
- 데이터 모델을 Prisma schema에 작성하거나 기존 schema 업데이트
Introspection 워크플로
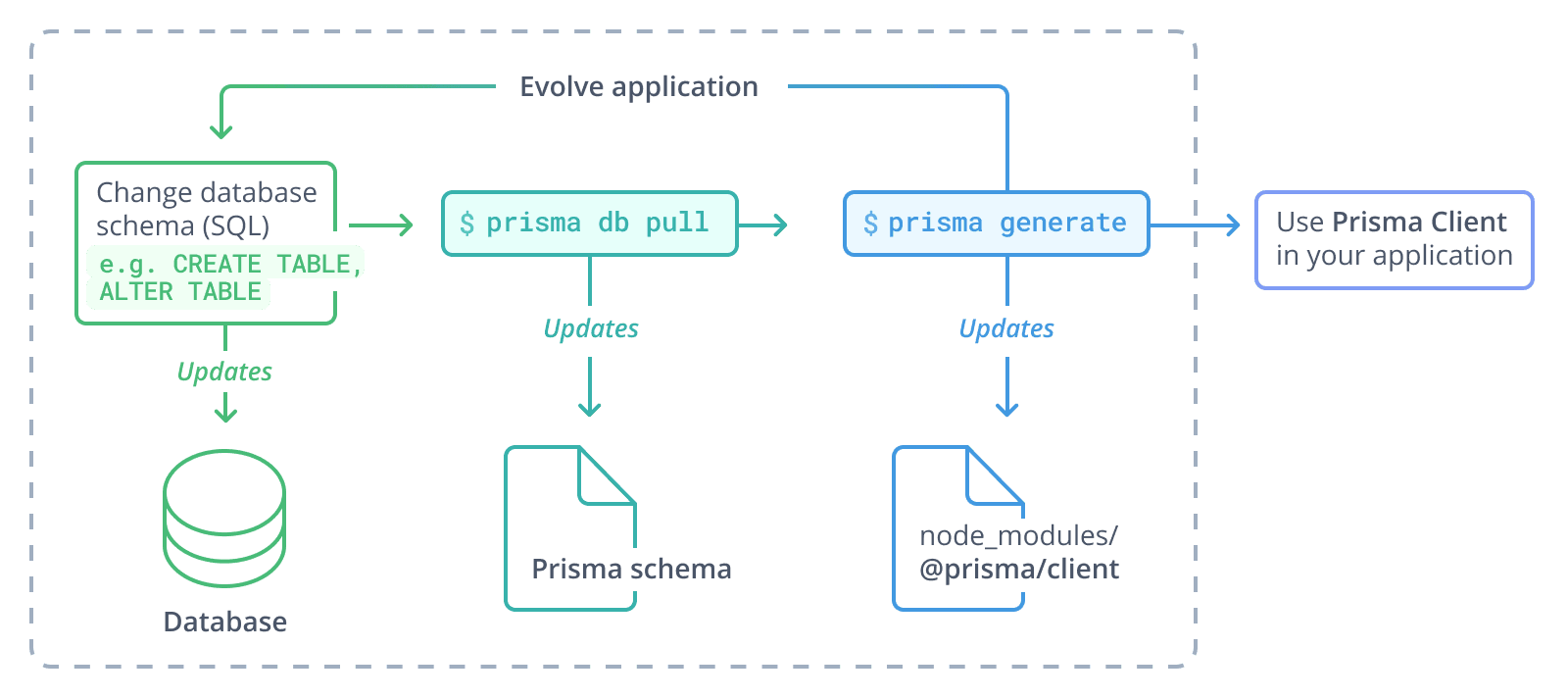
섹션 제목: “Introspection 워크플로”Prisma Migrate를 사용하지 않고 대신 일반 SQL이나 다른 마이그레이션 도구를 사용하는 프로젝트의 일반적인 워크플로는 다음과 같습니다:
- 데이터베이스 스키마 변경(예: 일반 SQL 사용)
prisma db pull실행하여 Prisma schema 업데이트prisma generate실행하여 Prisma Client 업데이트- 애플리케이션에서 업데이트된 Prisma Client 사용
애플리케이션을 발전시키는 과정에서 이 프로세스는 횟수 제한 없이 반복 가능하다는 점에 유의하세요.
규칙과 규약
섹션 제목: “규칙과 규약”Prisma ORM은 데이터베이스 스키마를 Prisma schema의 데이터 모델로 변환할 때 여러 규약을 사용합니다:
- 모델, 필드 및 enum 이름
필드, 모델, enum 이름(식별자)은 문자로 시작해야 하며 일반적으로 밑줄, 문자, 숫자만 포함해야 합니다. 각 식별자에 대한 네이밍 규칙과 규약은 해당 문서 페이지에서 확인할 수 있습니다:
- 모델 이름 지정
- 필드 이름 지정
- enum 이름 지정
식별자에 대한 일반 규칙은 다음 정규식을 준수해야 한다는 것입니다:
[A-Za-z][A-Za-z0-9_]*- 유효하지 않은 문자 정제
Introspection 중에 유효하지 않은 문자는 정제됩니다:
- 식별자에서 문자 앞에 나타나면 제거됩니다.
- 첫 문자 이후에 나타나면 밑줄로 대체됩니다.
또한 변환된 이름은 원래 이름을 유지하기 위해 @map 또는 @@map 을 사용해 데이터베이스에 매핑됩니다.
예시로 다음 테이블을 살펴보겠습니다:
CREATE TABLE "42User" ( _id SERIAL PRIMARY KEY, _name VARCHAR(255), two$two INTEGER );Prisma ORM에서는 테이블 이름의 앞 42, 컬럼의 앞 밑줄, 그리고 $ 가 허용되지 않으므로, introspection은 이 이름들이 Prisma ORM의 네이밍 규약을 따르도록 @map 및 @@map attributes를 추가합니다:
model User { id Int @id @default(autoincrement()) @map("_id") name String? @map("_name") two_two Int? @map("two$two")
@@map("42User") }- 정제 후 중복 식별자
정제 결과 식별자가 중복되면 즉시 오류 처리되지는 않습니다. 오류는 나중에 발생하며 수동으로 수정해야 합니다.
다음 두 테이블의 경우를 생각해 봅시다:
CREATE TABLE "42User" ( _id SERIAL PRIMARY KEY );
CREATE TABLE "24User" ( _id SERIAL PRIMARY KEY );이 경우 introspection 결과는 다음과 같습니다:
model User { id Int @id @default(autoincrement()) @map("_id")
@@map("42User") }
model User { id Int @id @default(autoincrement()) @map("_id")
@@map("24User") }prisma generate 로 Prisma Client를 생성하려고 하면 다음 오류가 발생합니다:
npm
pnpm
yarn
bun
npx prisma generate $ npx prisma generate Error: Schema parsing error: The model "User" cannot be defined because a model with that name already exists. */} schema.prisma:17 | 16 | } 17 | model User { |
Validation Error Count: 1이 경우 Prisma schema에서는 중복 모델 이름이 허용되지 않으므로, 생성된 두 User 모델 중 하나의 이름을 수동으로 변경해야 합니다.
- 필드 순서
Introspection은 데이터베이스의 해당 테이블 컬럼 순서와 동일한 순서로 모델 필드를 나열합니다.
- attribute 순서
Introspection은 다음 순서로 attributes를 추가합니다(이 순서는 prisma format 에도 동일하게 반영됨):
- 블록 레벨:
@@id,@@unique,@@index,@@map - 필드 레벨 :
@id,@unique,@default,@updatedAt,@map,@relation
- 관계
Prisma ORM은 데이터베이스 테이블에 정의된 외래 키를 relations로 변환합니다.
- 일대일 관계
Prisma ORM은 테이블의 외래 키에 UNIQUE 제약이 있는 경우 데이터 모델에 one-to-one 관계를 추가합니다. 예:
CREATE TABLE "User" ( id SERIAL PRIMARY KEY ); CREATE TABLE "Profile" ( id SERIAL PRIMARY KEY, "user" integer NOT NULL UNIQUE, FOREIGN KEY ("user") REFERENCES "User"(id) );Prisma ORM은 이를 다음 데이터 모델로 변환합니다:
model User { id Int @id @default(autoincrement()) Profile Profile? }
model Profile { id Int @id @default(autoincrement()) user Int @unique User User @relation(fields: [user], references: [id]) }- 일대다 관계
기본적으로 Prisma ORM은 데이터베이스 스키마에서 찾은 외래 키에 대해 데이터 모델에 one-to-many 관계를 추가합니다:
CREATE TABLE "User" ( id SERIAL PRIMARY KEY ); CREATE TABLE "Post" ( id SERIAL PRIMARY KEY, "author" integer NOT NULL, FOREIGN KEY ("author") REFERENCES "User"(id) );이 테이블들은 다음 모델로 변환됩니다:
model User { id Int @id @default(autoincrement()) Post Post[] }
model Post { id Int @id @default(autoincrement()) author Int User User @relation(fields: [author], references: [id]) }- 다대다 관계
Many-to-many 관계는 관계형 데이터베이스에서 일반적으로 relation tables로 표현됩니다.
Prisma ORM은 Prisma schema에서 다대다 관계를 정의하는 두 가지 방식을 지원합니다:
- 암시적 다대다 관계 (Prisma ORM이 내부적으로 relation table을 관리)
- 명시적 다대다 관계 (relation table이 model로 존재)
암시적 다대다 관계는 Prisma ORM의 relation table 규약을 따를 때 인식됩니다. 그렇지 않으면 relation table은 Prisma schema에서 model로 렌더링되며(따라서 명시적 다대다 관계가 됨) 처리됩니다.
이 주제는 Relations 문서 페이지에서 자세히 다룹니다.
- 관계 구분(Disambiguating)
Prisma ORM은 일반적으로 @relation 속성에서 필요하지 않다면 name 인수를 생략합니다. 이전 섹션의 User ↔ Post 예시를 살펴보세요. @relation 속성에는 references 인수만 있고, 이 경우 name은 필요하지 않으므로 생략됩니다:
model Post { id Int @id @default(autoincrement()) author Int User User @relation(fields: [author], references: [id]) }Post 테이블에 두 개의 외래 키가 정의되어 있다면 name이 필요합니다:
CREATE TABLE "User" ( id SERIAL PRIMARY KEY ); CREATE TABLE "Post" ( id SERIAL PRIMARY KEY, "author" integer NOT NULL, "favoritedBy" INTEGER, FOREIGN KEY ("author") REFERENCES "User"(id), FOREIGN KEY ("favoritedBy") REFERENCES "User"(id) );이 경우 Prisma ORM은 전용 relation 이름을 사용해 relation을 구분(disambiguate)해야 합니다:
model Post { id Int @id @default(autoincrement()) author Int favoritedBy Int? User_Post_authorToUser User @relation("Post_authorToUser", fields: [author], references: [id]) User_Post_favoritedByToUser User? @relation("Post_favoritedByToUser", fields: [favoritedBy], references: [id]) }
model User { id Int @id @default(autoincrement()) Post_Post_authorToUser Post[] @relation("Post_authorToUser") Post_Post_favoritedByToUser Post[] @relation("Post_favoritedByToUser") }생성된 Prisma Client API에서 더 친숙하게 보이도록 Prisma-ORM 레벨의 relation 필드 이름은 원하는 대로 변경할 수 있습니다.
기존 스키마로 Introspection
섹션 제목: “기존 스키마로 Introspection”기존 Prisma Schema가 있는 관계형 데이터베이스에서 prisma db pull을 실행하면, 스키마에 수동으로 적용한 변경 사항과 데이터베이스에서 발생한 변경 사항을 병합합니다. MongoDB의 경우 현재 Introspection은 초기 데이터 모델 생성을 위해 한 번만 수행하는 용도로 설계되어 있습니다. 이를 반복 실행하면 아래에 나열된 것과 같은 사용자 정의 변경 사항이 손실됩니다.
관계형 데이터베이스의 Introspection은 다음 수동 변경 사항을 유지합니다:
model블록 순서enum블록 순서- 주석
@map및@@map속성@updatedAt@default(cuid())(cuid()는 Prisma-ORM 레벨 함수)@default(uuid())(uuid()는 Prisma-ORM 레벨 함수)- 사용자 지정
@relation이름
참고 : 데이터베이스 레벨에서 모델 간 relation만 감지됩니다. 즉, 외래 키가 반드시 설정되어 있어야 합니다.
스키마의 다음 속성은 데이터베이스에 의해 결정됩니다:
model블록 내 필드 순서enum블록 내 값 순서
참고 : 모든
enum블록은model블록 아래에 나열됩니다.
- 강제 덮어쓰기
수동 변경 사항을 덮어쓰고, introspection된 데이터베이스만을 기준으로 스키마를 생성하며 기존 Prisma Schema를 무시하려면 db pull 명령에 --force 플래그를 추가하세요:
npm
pnpm
yarn
bun
npx prisma db pull --force사용 사례는 다음과 같습니다:
- 기반 데이터베이스에서 생성된 스키마로 처음부터 다시 시작하고 싶을 때
- 스키마가 유효하지 않아 introspection을 성공시키기 위해
--force를 반드시 사용해야 할 때
데이터베이스 스키마의 일부만 Introspection하기
섹션 제목: “데이터베이스 스키마의 일부만 Introspection하기”데이터베이스 스키마의 일부만 Introspection하는 기능은 Prisma ORM에서 아직 공식적으로 지원되지 않습니다.
하지만 Prisma 스키마에 반영하고 싶은 테이블에만 접근 권한이 있는 새 데이터베이스 사용자를 만든 뒤, 해당 사용자로 introspection을 수행하면 이를 달성할 수 있습니다. 그러면 introspection 결과에는 새 사용자가 접근 가능한 테이블만 포함됩니다.
목표가 Prisma Client 생성에서 특정 모델을 제외하는 것이라면, Prisma 스키마의 모델 정의에 @@ignore 속성을 추가할 수 있습니다. 무시된 모델은 생성된 Prisma Client에서 제외됩니다.
지원되지 않는 기능에 대한 Introspection 경고
섹션 제목: “지원되지 않는 기능에 대한 Introspection 경고”Prisma Schema Language(PSL)는 Prisma ORM이 지원하는 대상 데이터베이스의 기능 대부분을 표현할 수 있습니다. 하지만 Prisma Schema Language가 아직 표현하지 못하는 기능과 동작이 존재합니다.
이러한 기능에 대해서는 Prisma CLI가 데이터베이스에서 해당 기능 사용을 감지해 경고를 반환합니다. 또한 Prisma CLI는 해당 기능이 사용된 모델 및 필드에 Prisma 스키마 주석을 추가합니다. 경고에는 우회 방법 제안도 포함됩니다.
prisma db pull 명령은 다음과 같은 미지원 기능에 대해 경고를 표시합니다:
- 파티셔닝된 테이블
- PostgreSQL Row Level Security
- 인덱스 정렬 순서,
NULLS FIRST/NULLS LAST - CockroachDB row-level TTL
- 주석
- PostgreSQL deferred constraints
- Check Constraints (MySQL + PostgreSQL)
- Exclusion Constraints
- MongoDB $jsonSchema
- 표현식 인덱스
지원 예정 기능 목록은 GitHub (topic:database-functionality 라벨)에서 확인할 수 있습니다.
- 지원되지 않는 기능에 대한 Introspection 경고 우회 방법
관계형 데이터베이스를 사용 중이며, 이전 섹션에 나열된 기능 중 하나라도 사용 중이라면:
- 드래프트 마이그레이션을 생성합니다:
npm
pnpm
yarn
bun
npx prisma migrate dev --create-only- 경고에 표시된 기능을 추가하는 SQL을 작성합니다.
- 드래프트 마이그레이션을 데이터베이스에 적용합니다:
npm
pnpm
yarn
bun
npx prisma migrate dev